DATASEM '99, 19th annual conference on the Current
Trends in Databases and Information Systems
Brno, hotel SANTON,
24.-26.10.1999, MU Brno
Zvaná přednáška
(Invited Lecture), ed.: Karel Richta
Quasi-nezávislé provozní databáze a dvouvrstvý datový sklad s
využitím databází dimenzí
Ing. Petr Vršek - SOFTMODEL, Dobrovského 32, 170 00 PRAHA
7
vrsek@softmodel.cz
Abstrakt. Zkušenosti ukazují, že je
z důvodu konsolidace dat možné, vhodné a někdy i nutné budovat provozní
aplikace (OLTP) přímo nad dynamickým datovým skladem (DDW) nebo alespoň nad
quasi-nezávislými provozními databázemi (QIODB) s výhodným využitím
databází dimenzí (DBD). Navrhovaný datový sklad je tvořen ze dvou vrstev,
z dynamického datového skladu a z vločkového datového skladu (SFDW). Příspěvek ukazuje takovou
architekturu, v níž provozní aplikace operují nad nezávislými provozními
databázemi, ale přitom je stále dodržována konsistence údajů mezi těmito
databázemi a dvouvrstvým datovým skladem. Tato nezávislost musí mít samozřejmě určitá omezení, abychom této
konsistence dosáhli. Předkládaný článek tato omezení stanoví, odůvodňuje
existenci této vícevrstvé databázové architektury a diskutuje její
vlastnosti.
Klíčová slova. On Line Transaction Processing (OLTP),
Dynamic Data Warehouse (DDW), Snowflake Data Warehouse (SFDW), Quasi Independent
Operational Database (QIODB), Database of Dimensions (DBD), Structural
Metascheme Database (SMDB).
- Úvod
Cílem příspěvku je poukázat na principiální nemožnost konsolidace
nesourodých heterogenních dat z různých zdrojů v jednotném datovém
skladu (ačkoliv je to často popisováno jako snadná záležitost) a navrhnout
určité metodické předpoklady k tomu, aby k této nesourodosti a heterogenitě
vůbec nedocházelo a jestliže k ní z
nejrůznějších důvodů dojít musí, aby k ní docházelo v co
nejmenší míře.
Část literatury týkající se datových skladů vytěsňuje provozní systémy OLTP
ze svého zorného úhlu, považuje je za téměř nezávislou záležitost a zabývá se
až ukládáním konsolidovaných dat do struktur typu hvězda či sněhová vločka.
Samotná konsolidace se většinou nepovažuje za podstatný problém, ačkoliv je to
problém kardinální.
V pojetí tohoto příspěvku jsou systémy OLTP pojímány jako integrální
součást jedné základní části datového skladu (t.zv. Dynamic Data Warehouse),
čímž se problém konsolidace redukuje pouze na skutečně neintegrovatelné
provozní subsystémy.
Domnívám se, že tak jako tvůrci datových skladů musí brát ve vlastním zájmu
v úvahu existenci provozních systémů a jejich potřeb, tak též tvůrci
provozních systémů musí brát v úvahu existenci integrovaných informačních
systémů a této koncepci se přizpůsobit. Modernizace provozního SW v tomto
smyslu je logickým vývojovým stupněm v rámci vývojové spirály od tuhé
centralizace (mainfr
amy) přes bezbřehou
nevázanost (PC) k rozumně pojetému integrovanému informačnímu systému podniku
budovaným nad dynamickým datovým skladem v součinnosti s quasi-nezávislými
provozními databázemi a databázemi dimenzí.
Důležitá poznámka: Bude-li kdekoliv v tomto příspěvku použit termín
IIS nebo integrovaný informační systém podniku, je slovem "podnik" myšlena
část světa (universa), pro níž systém budujeme. Veškeré popisované vlastnosti
tedy platí jak pro informační systém jedné malé firmy, tak pro informační
systém podnikového koncernu nebo města,
regionu, státu....
- Dvouvrstvý datový sklad
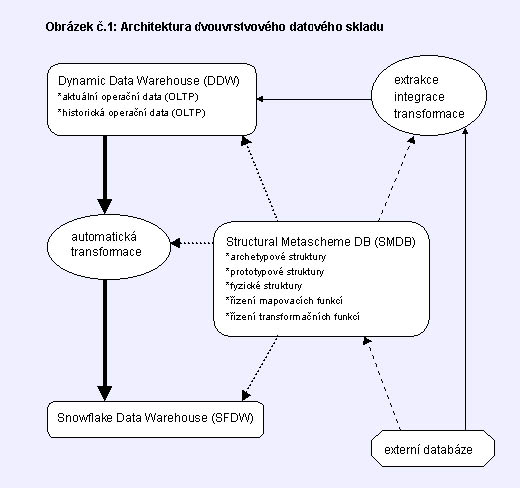
Na obrázku č.1 je navržena architektura dvouvrstvého datového skladu, jejíž
jednotlivé komponenty jsou popsány dále:
- DDW
Jedna vrstva datového skladu, označená jako
DDW (Dynamic Data Warehouse), má stabilní databázovou strukturu vytvořenou
převážně kusovníkovými, propojovacími a entitně - podtypovými archetypy
(entitními vazbami) s dokonalým mapováním historie a slouží jednak jako
primární databáze datového skladu
celého podnikového integrovaného informačního systému pro ukládání
elementárních dat, jednak jako provozní
(OLTP) databáze nad kterou operuje množina provozních uživatelských
programů. Důležitou vlastností této databázové struktury je její relativní
stabilita v průběhu času a tedy i v průběhu životního cyklu celého
podnikového informačního systému. Tato vrstva je též vhodná pro kladení
mimořádných sofistikovaných dotazů "ad hoc".
- SFDW
Druhá vrstva datového skladu, označená jako SFDW (Snowflake Data
Warehouse), má silně nestabilní databázovou strukturu (generovanou
v čase z vývoje dat v DDW) vytvářenou převážně stromovými
hierarchickými dimenzionálními entitními strukturami (platnými pouze
v určitém časovém intervalu) a množinou at
omických a neatomických entit faktů (platnými též
v určitém časovém intervalu). Tato vrstva slouží jako
sekundární databáze datového
skladu celého podnikového integrovaného informačního systému pro
ukládání agregovaných dat a tedy pro statistiku, dolování dat a datová tržiště. Nad touto vrstvou tedy operuje
řada různých rutinních dotazovacích programů, často periodicky spouštěných.
- SMDB
Velmi důležitou komponentou je databáze obsahující metadata uložená podle
strukturálního metaschématu, t.zv. Structural Metascheme Database (SMDB),
obsahující především archetypové struktury, prototypové struktury, fyzické
struktury, řízení mapovacích funkcí a řízení transformačních funkcí.
Pod pojmem "archetypová struktura" rozumíme základní konstrukční prvek
konceptuálního datového schématu vyšší úrovně, skládající se z více entit a
vztahů mezi nimi bez konkretizace atributů entit. Je to šablona pro tvorbu
větších konceptuálních datových schémat. Příklady různých základních
archetypů: "generalizace-specializace", "celek-čá
st", "nepovinný číselník", "povinný číselník",
"požadovaný číselník", "sémantická propojovací vazba", "sémantická kusovníková
vazba". Viz [1].
Pod pojmem "prototypová struktura" rozumíme konkretizaci archetypu co se
týče atributů entit a jejich datových typů.
Pod pojmem "fyzická struktura" rozumíme konkretizaci prototypu na jeho
aplikaci v konkrétních databázích.
SMDB obsahuje též databázové struktury pro ukládání řídících mapovacích a
transformačních funkcí závislých především na prototypových strukturách a může
obsahovat i navazující struktury pro ukládání definic dotazů a evidenci
provádění dotazů.
Dimenze a fakta
V malých prakticky ad-hoc navrhovaných OLTP (provozních) informačních
systémech se běžně navrhují databázové struktury bez uvažování dalších
souvislostí a případných možných návazností na jiné informační systémy či na
výhledovou databázovou integraci s budoucím integrovaným informačním
systémem podniku.
S rozlišováním dimenzí a faktů se setkáváme u velkých datových skladů,
velmi zřídka však u malých provozních systémů. Při návrhu struktury
quasi-nezávislých provozních databází ovšem musíme pojmy "dimenze" a "fakta"
rozlišovat, protože jedině tímto způsobem můžeme dospět k žádanému cíli -
konsistentním datům na všech úrovních IIS.
Obecně se dá říci, že "dimenzemi" u běžného provozního informačního systému
vybudovaného nad relační databází jsou různé číselníky, kódovníky, rejstříky,
katalogy či nomenklatury (angl. "nomenclature"). "Fakty" jsou údaje závislé na
jedné či několika dimenzích. Jedním z
rozlišovacích znaků je zde kvantita: "dimenzionální
tabulky" mají většinou řádově menší počet vět než tabulky ostatní. Tabulky
provozní databáze můžeme tedy rozdělit na "tabulky kvalitativní" a "tabulky
kvantitativní".
Velmi důležitá poznámka týkající se nomenklatur (číselníků): Pod tímto pojmem
se v tomto příspěvku chápe tabulka s jedním atributem ("kód") nebo se
dvěma atributy ("kód", "vysvětlení kódu") nebo i s více atributy ("kód",
"mezinárodní zkratka", "krátký text český", "krátký text anglický",
"dl
ouhý text český", "dlouhý text
anglický",...), přičemž žádný z doplňkových atributů ke kódu není faktem,
ale lidsky srozumitelným popisem kódu. Příklad nomenklatury přirozených čísel:
"1"- "jedna", "2" - "dvě",...
Dimenzemi jsou např.: subjekt, objekt, lokalizace, čas, záležitost, diagnóza,
pohlaví, .... Fakta jsou např.: počet, plocha, cena, poplatek,...
Z výše uvedených odstavců je cítit určitá rozpornost. Jak to, že např.
subjekt je označován jako dimenze? Vždyť subjektů můžeme v systému evidovat
někdy i miliony, jak to že je to "kvalitativní údaj"? Není to omyl?
Určitě není. Čtenář z vlastní praxe jistě ví, že v t.zv.
"číselnících" (nomenklaturách) se uchovávají většinou povolené hodnoty určitého
atributu entity (definice domény číselníkovým výčtem), které mají jednotky až
stovky, vyjímečně tisíce výskytů. Jsou to např. barva, druh pozemku, typ
právnické osoby, číslo paragrafu zákona,...
Existují ovšem nomenklatury, které mají nejen tisíce, ale miliony položek a
tyto položky mají ještě navíc svůj interval platnosti. Typickými příklady jsou
např. osoby, nemovitosti nebo adresy.
Zde opět důležité upozornění: nomenklatura osob obsahuje ideálně pouze
jednoznačné generované kódy osob, nikoliv bohužel stále používané
indiskrétní RČ obsahující i fakt datum narození a fakt pohlaví. Ostatní
údaje o osobách, které se běžně uchovávají v t.zv. "registrech osob",
nejsou dimenzionálními údaji, ale fakty závislými na nomenklatuře (dimenzi)
osob, někdy i vícenásobně, ale často současně i na zcela jiných dimenzích!!!
Nemě
ly by se tedy ukládat do jedné
databázové tabulky "osoba", což je běžným zvykem, ale do řady samostatných
tabulek faktů. Příklady: "plat" (koho - období), "dluh" (koho - komu - období),
"příjmení" (koho - období), "trvalé bydliště" (koho - adresa (=územní či
lokalizační dimenze) - období).
V provozních databázích se běžně ukládají "data o občanech", "data o
nemovitostech", "data o vztahu občanů a nemovitostí" atd., čili ukládáme další
fakta závislá na jiných, naprosto nekonsistetntních a nekontrolovatelných
faktech. V tom je právě jádro celého problému. Do databáze ukládáme určitá
fakta patřící do vícerozměrného prostoru, přičemž některé osy tohoto prostoru
(dimenze) vůbec neevidujeme nebo evidujeme zkresleně.
Proto, aby se mohla konsolidovat data (rozuměj fakta) z různých
nezávislých databází v centrálním datovém skladu, musí mít všechny tyto
databáze v čase konsistentní dimenze týkající se těchto faktů, čili že
musíme vytvořit distribuovanou dimenzionální databázovou strukturu.
Jedním z největších problémů je údržba konsistentní dimenze velkého
rozsahu časově proměnná jak co do počtu aktuálně zahrnutých prvků (na všech
hierarchických úrovních stromové dimenziální struktury), tak co do změny tvaru
stromové dimenziální struktury. Údržbu takovéto dimenze kva
litně zvládne DDW.
Příklad: Představme si, že máme dvě dimenze: "osoby" a "křesťanský letopočet"
a jeden fakt: "příjem". Uvažujme, že máme čtyři nezávislé provozní informační
systémy, které všechny evidují příjmy osob v jednotlivých rocích. Časová
dimenze "křesťanský letopočet" je zcela bezkonfliktní, protože ve všech
existujících informačních systémech na světě se dá automaticky vygenerovat a má
zcela jednoznačné a v čase neměnné hodnoty.
Dimenze "osoba" je právě kamenem úrazu. Neexistuje-li žádný jednoznačný
referenční zdroj této v čase se vyvíjející dimenze (on-line sdílená
bezchybná nomenklatura rodných čísel nebo optimálně jim na úroveň postavených
kódů případně v kombinaci s individuálními čipovými kartami vyrobenými
z tohoto referenčního zdroje), nemůže se s touto situací žádný
informační systém rozumně vypořádat. Identifikátory osob se potom evidují
v lokálních systémech bez kontroly.
Při konsolidaci faktů (příjmů) různých osob v různých létech
z různých provozních informačních systémů do centrálního datového skladu
dochází k neřešitelným situacím, protože mohou nastat například tyto
kombinace:
- V roce 1995 vztahujeme příjmy dvou osob pouze na jednu z nich
(neodpovídá ani počet evidovaných osob), protože druhá osoba má
v některých informačních systémech omylem identické RČ s první
osobou.
- V roce 1995 nesčítáme příjmy jedné osoby ze všech informačních
systémů dohromady (uvažujeme jednu osobu jako více osob), protože tatáž osoba
má omylem v některých informačních systémech jiné RČ.
- Domníváme se, že osoba A má v roce 1996 menší příjmy než v roce
1995, ale je to způsobeno tím, že v jednom provozním systému došlo ku
smazání osoby následkem oznámení o jejím úmrtí a ve druhém provozním systému
má osoba B omylem stejné RČ jako osoba A, čili osoba B "pracuje"
n
a účet mrtvé osoby A.
Jaké jsou vlastně rozdíly mezi izolovanými běžnými malými provozními
firemními systémemy a informačním systémem nějakého velkého podniku
s dobrým jednotným informačním systémem ?
Především v tom, jak se pracuje s dimenzemi. U běžného provozního
firemního systému se s dimenzemi většinou nepracuje, neuvažuje se
s kooperací s jakýmkoliv DDW.
U dobrého informačního systému velkého podniku jsou dimenzemi jasně a
jednoznačně definované např. vlastní výrobky, výrobci, regiony... Hodnoty těchto
dimenzí se při aktualizaci replikují do lokálních provozních systémů
v rámci jednotného IIS. Fakta jsou zde především peníze a počty kusů.
Pro běžný podnikový informační systém bohužel většinou platí:
- Jednotný informační systém je pouze deklarován, většinou se jedná o
množinu nezávislých provozních systémů, které nemají společně udržované
dimenze, někde se udržují nezávisle v každém ze systémů, někde se
neudržují vůbec - považují se za fakta.
- Extrakce, integrace a transformace dat (faktů) do centrálního datového
skladu je principiálně vyloučena
- Existuje uživatelský zájem o datový sklad individuálních dat i agregátů,
ale toto přání je vzhledem k nekonsistenci dimenzí nesplnitelné.
Pro podnikový informační systém může platit:
- Jednotný integrovaný informační systém je skutečně realizován. Skládá se
především z primární centrální databáze DDW (dokonale v čase
evidující veškeré dimenze a jejich používané hodnoty a též veškerá relevantní
fakta z quasi-nezávislých provozních databází) a v případně požadovaných
agregátů a datových tržišť se skládá i ze
sekundární databáze SFDW. Součástí IIS je i množina provozních subsystémů
operujících nad quasi-nezávislými provozními databázemi, které respektují
dimenze DDW, využívají jejich replikovaných hodnot a pomocí jasně
definovaných transakcí v takto
existujícím distribuovaném systému (viz [3] a [4]) mohou dimenzionální hodnoty
DDW i aktualizovat. Quasi-nezávislé provozní databáze se většinou vytvářejí
pro evidenci nových aktuálních faktů.
Extrakce, integrace a transformace dat
(faktů) do centrálního datového skladu se potom provádí velmi snadno pomocí
automatické datové pumpy řízené metaschématem systému řízení datového skladu.
Je zájem o rychlé provozní subsystémy s konsistentními dimenzemi a
datový sklad individuálních dat i agregátů
s rychlým přístupem k nim a toto přání je vzhledem k navrhované
architektuře uskutečnitelné.
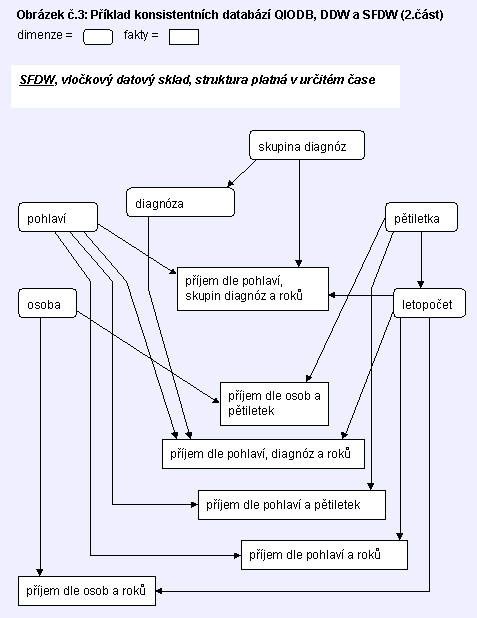
Schématický příklad architektury tří kooperujících databází je na obrázku č.2
a 3.
- Quasi-nezávislá provozní databáze (QIODB)
Konceptuální datové schéma (ER - diagram) této
databáze navrhujeme dle běžných zvyklostí, aplikačních potřeb a požadavků
koncových uživatelů pouze s tím rozdílem, že plně respektujeme dimenze
již existující primární databáze (DDW). Vlastní existence QIODB je odůvodněna
pouze provozní výhodností (rychlost,
bezpečnost), nikoliv však logikou samotného zpracování. Tím, že připustíme
existenci QIODB, vytvoříme vlastně distribuovaný databázový systém DDBS a
musíme konkrétně vyřešit všechny transakční problémy s tím spojené, viz
[3]. Prakticky dostačující řešení je
například metoda "Transakční replikace s Immediate-Update odběrateli",
viz [4]. "Distribuovanost" zde ovšem stačí řešit pouze na úrovni dimenzí,
nikoli faktů. Stále však platí, že logicky ideální je pracovat i
v oblasti OLTP přímo nad DDW.
V rámci IIS podniku může tedy vedle dvouúrovňového datového skladu
(DDW a SFDW) existovat řada QIODB pro různé evidence - viz obr. 2 a 3.
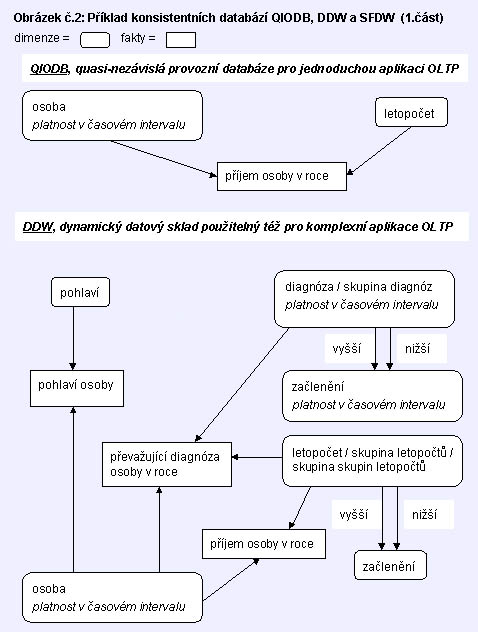
Na obr.2 je jako jednoduchý příklad znázorněna databáze jednoduché aplikace
evidence ročních příjmů osob, která replikuje z DDW nejnižší úroveň
dimenziální struktury "osoba", sama si generuje nejnižší úroveň dimenzionální
struktury "letopočet" a zcela nezávisle eviduje fakty "příjem osoby
v roce". Pro
to tedy název této
databáze "quasi-nezávislá": je závislá na DDW v dimenzích, jejichž data
nelze automaticky generovat a je nezávislá na DDW v oblasti evidence těch
faktů, které jsou v ní zaznamenávány.
V případě, že se dostaví osoba, která ještě není v QIODB
evidována (předpokládáme, že v ustáleném provozním stavu to není běžný
případ), musí být umožněno on-line napojení na DDW a pořízení kódu této osoby
(jako prvku dimenzionální struktury) do DDW v tom
případě, jestliže tam tento kód neexistuje, případně
pouhá verifikace tohoto kódu, jestliže tam již existuje. Potom musí následovat
jeho duplicitní záznam v QIODB. Dá se říci, že velmi důležitým vedlejším
účinkem diskutované jednoduché aplikace nad QIODB je i to, že tato aplikace není pouze zdrojem faktů
(příjem osoby v roce), což jej zdánlivě její hlavní a jediný úkol, ale
současně i zdrojem dimenzionálních dat dimenze osoba. Taková aplikace však
nemusí být v IIS jediná. Může existovat řada jiných jednoduchých aplikací nad jinými QIODB, jejichž úkolem je
evidovat jiné fakty, které jsou též zdrojem dimenze osoba.
Důležité ovšem je, aby byla on-line zajištěna konsistence dimenzionálních
prvků celého IIS, tedy DDW a všech QIODB. Pro fakty toto přísné hledisko
neplatí, ty se do DDW dají přenášet dávkově "datovou pumpou" a nevzniknou
žádné nekonsistence.
- Praktické výhody a nevýhody navrhované architektury
Pro časově náročný přenos faktů mezi QIODB a DDW se dá použít metoda
styčných souborů, které můžeme archivovat na CD-ROM, čímž současně
zabezpečujeme data pořízená do QIODB. Je-li cílem nějakého IIS přenášet data
přímo z QIODB do SFDW, čili provádět export + agregaci + import,
zjišťujeme, že tato přímá operace je nesmírně náročná na systémové zdroje,
nespolehliv
á (hrozí ztráty dat) a přitom
zdlouhavá. Daleko rychlejší, bezpečnější a transparentnější způsob je export
z QIODB, import do DDW a agregace do SFDW. Tím, že databáze QIODB a
DDW+SFDW (nebo dokonce QIODB a DDW a SFDW) jsou každá umístěna na jiném
diskovém prostoru obsluhovaném jiným
počítačem, zvyšujeme bezpečnost celého IIS
Aplikace nad QIODB, které nejsou zdrojem dimenzionálních dat, jsou velmi
jednoduše realizovatelné. Ačkoliv se jedná o distribuovaný systém v rámci
DDW, dimenzionální data se získávají bezproblémově jednoduchou replikací
z DDW do QIODB.
Aplikace nad QIODB, které jsou zdrojem dimenzionálních dat, jsou již
náročnější distribuované systémy v rámci DDW a musíme používat vhodných
metod transakčních replikací. Zde je vždy třeba uvážit, není-li vhodnější
napsat OLTP aplikaci přímo nad DDW. Aplikaci je také možno rozdělit na dvě,
z nichž první, zdroj dimenze, operuje přímo nad DDW a druhá, zdroj faktů,
operuje nad replikovanými dimenzionálními daty a nad fakty v QIODB,
přičemž dimenzionální data
neaktualizuje.
Různé QIODB mohou mít v rámci svého životního cyklu proměnnou
databázovou strukturu. Tato struktura však musí být v dimenzionální
oblasti vždy zcela konsistentní s příslušnou dimenzionální oblastí DDW a
v oblasti faktů musí umožnit bezproblémový dávkový export do DDW, čemuž
musí přizpůsobit datové typy příslušných atributů.
Databáze dimenzí (DBD)
Pro rozsáhlé IIS může být vhodné udržovat jednotlivé velké dimenzionální
struktury v samostatných jednoúčelových databázích (databázích dimenzí)
na discích samostatných počítačů, odkud by se jednoduše replikovaly do DDW i
do jednotlivých QIODB, viz obr.4.
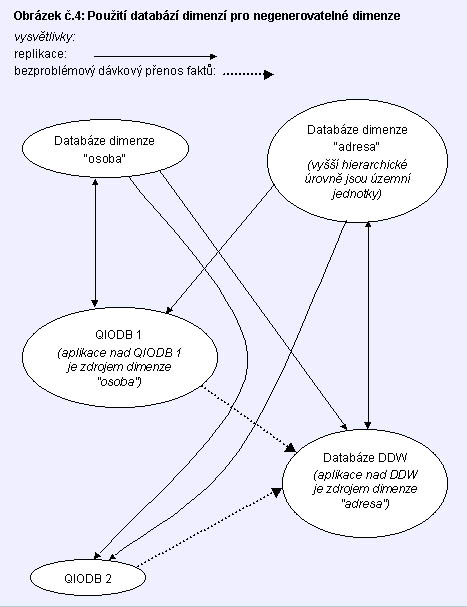
Takové DBD mohou být společné dokonce i pro několik quasi-nezávislých IIS
(DDW), které si potom mohou mezi sebou dávkově vyměňovat fakty. Vyměňují-li si
je bez existence těchto DBD, což je nyní běžné, dochází permanentně
k naprosto neřešitelným situacím, které z principu nemohou vyřešit
jakkoliv velké týmy "čističů dat", pracující ve všech datově
kooperujících institucích.
V databázích dimenzí navrhuji ukládat pouze nomenklatury, nikoliv fakty.
Tím, že např.existuje jedna databáze dimenze "občan", nemůže instituce,
spravující tuto databázi, shromažďovat žádné důvěrné fakty o občanech, protože
tato databáze vůbec žádné fakty neobsahuje. Důvěrné fakty o občanech se
ukládají do jednotlivých QIODB nebo DDW/SFDW obsahujících fakty. (IIS správy
důchodového zabezpečení, IIS finančních úřadů, IIS celní správy, IIS zdravotní
pojišťovny, IIS policie, IIS ob
ce,...).
Za bezpečnost a ochranu faktů obsažených v QIODB nebo v DDW/SFDW odpovídají
provozovatelé těchto databází a nikoliv provozovatelé jednotlivých databází
dimenzí, kteří s fakty nemají nic společného. Navíc je nutné, aby se k
některým nomenklaturám (např. generovaný kód občana) vytvářely pro interní
potřebu jednotlivých IIS šifrované aliasy těchto kódů. Každá databáze dimenzí
musí disponovat rozhraním, které bude pro oprávněné IIS poskytovat potřebné
služby.
Úvahy týkající se dimenze "osoba" jsou ovšem
na celostátní úrovni bezpředmětné do té doby, dokud nebude zrušen relikt zvaný
"rodné číslo" (obsahující citlivý fakt pohlaví a datum narození), jakýsi
dimenzionálně-faktový hybrid, který je bohužel v řadě institucí používán místo
interního anonymního identifikačního
kódu.
Obrovská výhoda existence celostátních databází dimenzí spočívá v tom,
že jednotlivé DDW si nemusí dimenze vytvářet a udržovat. Zdrojů dimenzí je
totiž relativně opravdu velmi málo.
Závěr
Tímto příspěvkem jsem chtěl ukázat, že při tvorbě IIS je vhodné
v první řadě vytvořit DDW. Ostatní komponenty jsou pouze nadstavbové. Pro
statistiku je to SFDW, pro jednoduché provozní OLTP aplikace to jsou
jednoúčelové databáze QIODB. Je-li OLTP aplikace příliš komplexní, je vhodné
jí naprogramovat př
ímo nad DDW. Jsou-li
některá automaticky negenerovatelná dimenzionální data příliš rozsáhlá a
ukazuje se, že řada provozních aplikací nad QIODB slouží jako zdroje této
dimenze nebo že je dokonce vhodné, aby se některá dimenze udržovala jednotně
pro několik nezávislých DDW, je vhodné
jednotně udržovat tato dimensionální data v databázi dimenzí. Má to nejen
výhodu systémovou, ale i provozní, protože režii aktualizace dimenze či čtení
dimenzionálních dat nese výkonný server databáze dimenzí a nikoliv malá
QIODB či jinak velmi vytížený DDW.
Citace, reference
[6] Gardner Stephen: Data Warehouse Architectures. NCR Corporation 1997
[5] Kimball Ralph: A dimensional Modeling Manifesto. DBMS - August 1997
[4] Microsoft Developer Conference: SQL Server 7.0 SPHINX (CD-ROM)
[3] Pokorný Jaroslav: Databázová abeceda. Science, Praha,1998
[7] Šanda Alfréd: Architektura DW dle Billa Inmona. CW 25/99 str.7
[8] Šanda Alfréd: Architektura DW podle Ralpha Kimballa. CW 26/99 str.7
[1] Vršek Petr: Archetypy v konceptuálních datových schématech. In: Sborník semináře "Moderní databáze",
Zlenice, 16. a 17.9.1997
[2] Vršek Petr: Dvouvrstvá architektura datového skladu. In: Sborník semináře
"Moderní databáze", Čelákovice, 9. a 10.6. 1998